참고 : 판다스 주요 명령어 모음집
https://pandas.pydata.org/Pandas_Cheat_Sheet.pdf

melt
파라미터 종류 : id_vars, value_vars, var_name, value_name
import pandas as pd
df=pd.DataFrame({'farm':['A농장','A농장','A농장','B농장','B농장','B농장','C농장','C농장','C농장'],
'produce' : ['토마토', '딸기', '마늘', '토마토', '딸기', '마늘', '토마토', '딸기', '마늘'],
'size':[10,7,3,9,6,2,8,5,1],
'weight':[33,27,24,22,18,18,11,9,12]})
df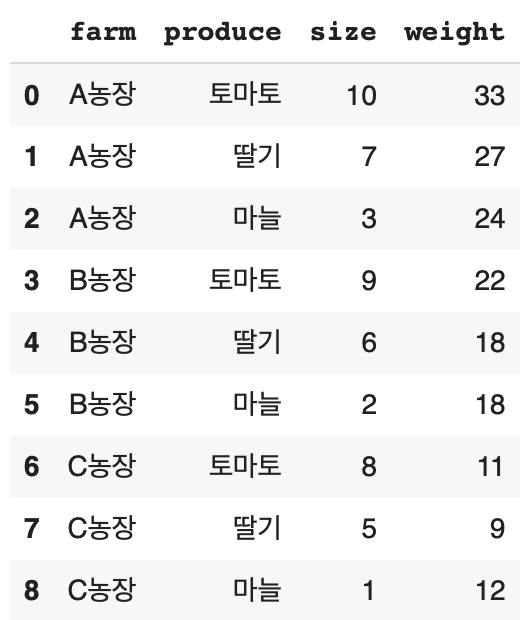
df.melt(id_vars = ['farm'])

variable, value 칼럼이 생겼다
farm 칼럼은 위치는 그대로이지만 값이 반복된다
produce, size, weight 칼럼이 variable 칼럼 값으로 들어갔다
그리고 그에 해당되는 실제 값들이 value에 들어갔다
*farm 칼럼의 값들은 variable에 맞게 반복된다
초록색을 produce, 주황색을 size, 파랑색을 weight 칼럼으로 보면 이해하기 쉬워진다
여기서 id_vars 파라미터에 produce 칼럼을 추가하면?
df.melt(id_vars = ['farm', 'produce'])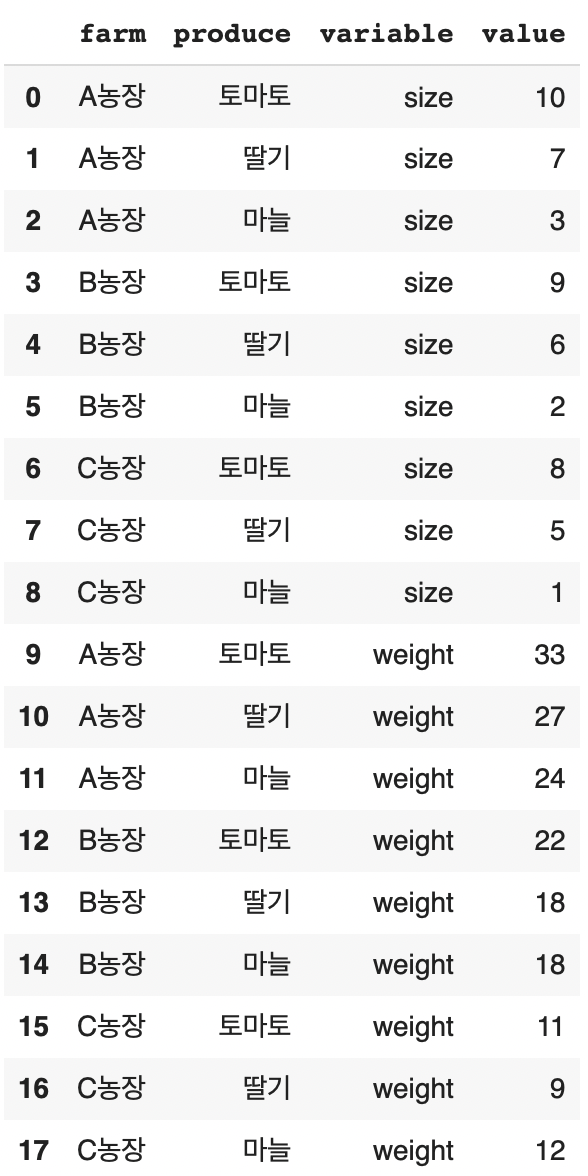
역시 variable, value 칼럼이 생겼다
farm, produce 칼럼은 위치는 그대로이지만 값이 반복된다
size, weight 칼럼이 variable 칼럼 값으로 들어갔다
그리고 그에 해당되는 실제 값들이 value에 들어갔다
*farm, produce 칼럼의 값들은 variable에 맞게 반복된다
df.melt(id_vars = ['farm', 'produce'],
var_name='produce_char',value_name='real_value')
variable과 value 칼럼 이름을 바로 설정할 수 있다
pivot
파라미터 종류 : index, columns, values
import pandas as pd
df=pd.DataFrame({'farm':['A농장','A농장','A농장','B농장','B농장','B농장','C농장','C농장','C농장'],
'produce' : ['토마토', '딸기', '마늘', '토마토', '딸기', '마늘', '토마토', '딸기', '마늘'],
'size':[10,7,3,9,6,2,8,5,1],
'weight':[33,27,24,22,18,18,11,9,12]})
df
df.pivot(index = 'produce',
columns = 'farm',
values = 'size')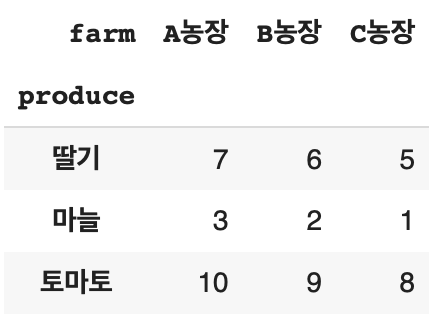
df.pivot(index = 'produce',
columns = 'farm',
values = 'weight')
'What I study > Python_details' 카테고리의 다른 글
| [Python] 코랩에 데이터(ex. csv 파일 등) 불러오기 (두 가지 방법) (0) | 2022.12.12 |
|---|---|
| [Python] value_counts() 와 sort_index() (0) | 2022.12.12 |
| [Python Numpy] np.concatenate()와 np.column_stack()의 차이점 (1) | 2022.12.06 |
| [Python Pandas] pandas 주요 명령어 모음집 (0) | 2022.12.02 |
| [Python] ModuleNotFoundError: No module named 'graphviz' 오류 해결하기 (0) | 2022.11.01 |