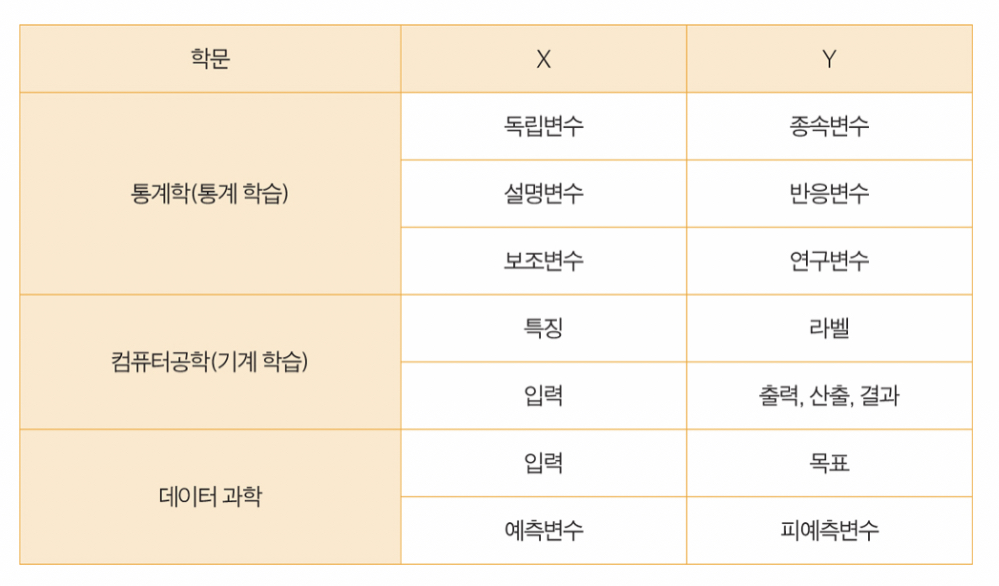
합집합 (UNION, UNION ALL)
SELECT [칼럼 이름]
FROM [테이블 A 이름]
(UNION or UNION ALL)
SELECT [칼럼 이름]
FROM [테이블 B 이름];
- UNION : 동일한 값 제외
- UNION ALL : 동일한 값도 포함
- 쿼리 A와 쿼리 B의 결과 값의 개수가 같아야 함
- ORDER BY는 쿼리 A에서 가져온 칼럼으로만 가능
💡 교집합 (INTERSECT), 차집합 (MINUS) *mysql에는 두 표현이 존재하지 않음 → JOIN으로 표현
교집합
SELECT [칼럼 이름]
FROM [테이블A 이름] AS A INNER JOIN [테이블 B 이름] AS B
ON A.[칼럼1 이름] = B.[칼럼2 이름] AND … AND A.[칼럼n 이름] = B.[칼럼 n 이름];
차집합 (A - B)
SELECT [칼럼 이름]
FROM [테이블A 이름] AS A LEFT JOIN [테이블 B 이름] AS B
ON A.[칼럼1 이름] = B.[칼럼2 이름] AND … AND A.[칼럼n 이름] = B.[칼럼 n 이름]
WHERE B.[칼럼 이름] IS NULL;
'What I study > mysql' 카테고리의 다른 글
| [MYSQL] 조건에 조건 더하기 (0) | 2023.01.09 |
|---|---|
| [MYSQL] 규칙 만들기 (0) | 2023.01.05 |
| [MYSQL] 데이터 그룹화하기 (0) | 2023.01.03 |
| [MYSQL] 원하는 데이터 만들기 (0) | 2023.01.02 |
| [MYSQL] 조건에 맞는 데이터 가져오기 (WHERE) (0) | 2023.01.02 |